AIは『答える道具』から『動く相棒』へ ― AIエージェント入門 (2026/05/25 new)
はじめに
AIといえば、「質問すると答えてくれる」「画像や文章を生成してくれる」程度の認識を持つ人もまだ多いかもしれません。
もうその認識は少し古くなりつつあります。
まずは簡単に、現在主流になっているAIが誕生してから現在に至るまでの流れについて触れてみましょう。
- 1.AIの誕生(ChatGPTの衝撃):
2022年末、誰もがAIと会話できるようになり、文章作成や要約が劇的に楽になった。
(「優秀な辞書・ライター」の登場) - 2.AIの進化(マルチモーダル化):
文字だけでなく、画像、音声、動画も扱えるようになり、AIの「五感」が発達した。 - 3.エージェントの普及(現在):
そして今、AIは「答える」だけでなく、「目的のために自ら動く(エージェント化)」フェーズへ。 例えば、「旅行の計画を立てて」と頼めば、ホテルを調べ、空き状況を確認し、予約一歩手前まで進めてくれるような、自律的な動きが普及し始めている。
これまでAIを使うには、私たちが『どう命令するか』を必死に考える必要がありました。
しかし、これからのAIエージェント時代は、私たちが『何をしたいか(ゴール)』を伝えるだけで、
AIが人間の手足となりそのプロセスを代行してくれるようになります。
この記事では、AI初心者などの入門者を対象にし、難しい技術用語を覚えることではなく、
「AIが自分の代わりに仕事をしてくれる時代」が来ていることをイメージしてもらえるように解説しています。
※この記事内で使用しているAI or AIエージェントは、全て無料プランを利用しています。

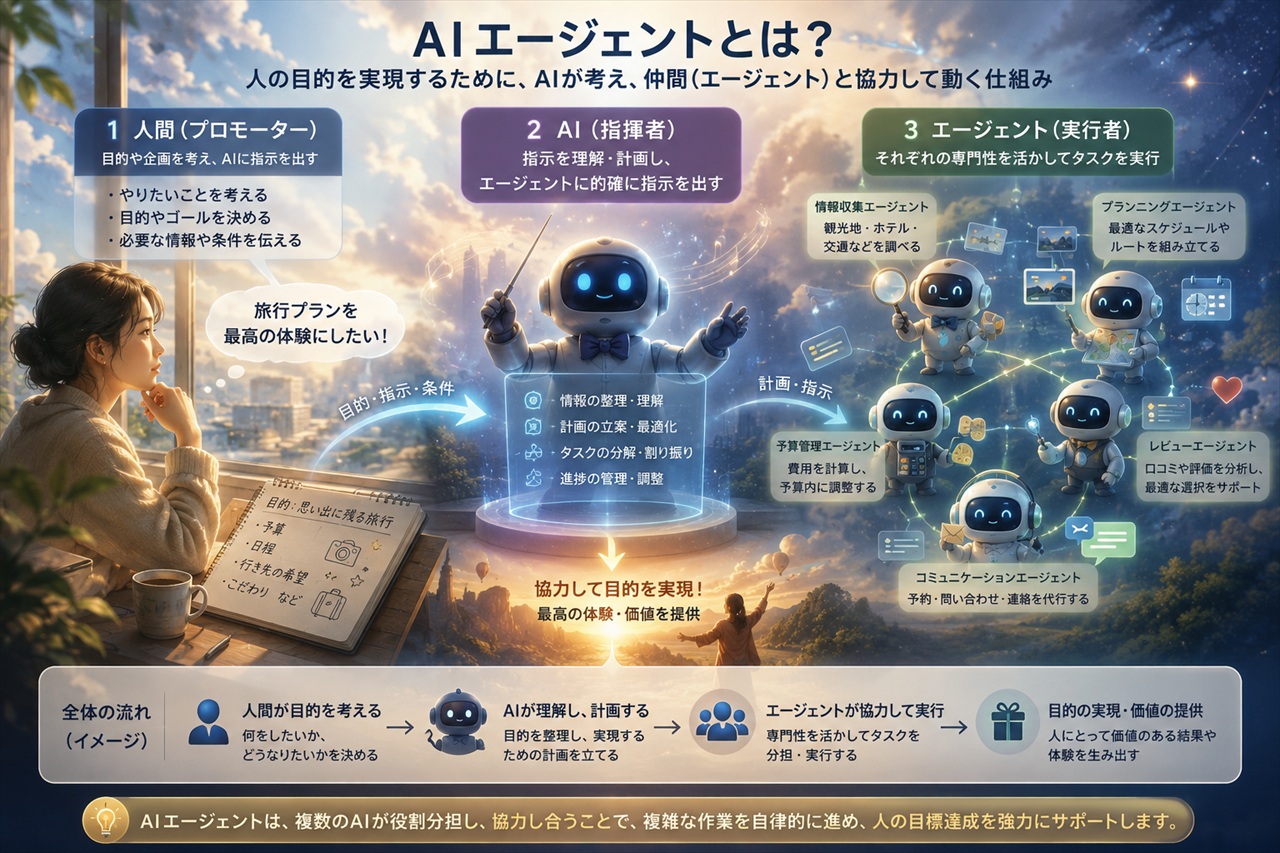
AIエージェントは何が違う
AIとAIエージェントの機能や役割の違いをまとめ、AIエージェントを身近に感じられる様に比喩で解説します。
1. AIとAIエージェントの機能・役割
-
AI:
人間がAIに質問等の目的を与えて、AIは回答・生成(文章・画像・音楽等)等の結果を返す頭脳。人間はその結果を基に作業を行う。
-
AIエージェント:
AIをベースに自律的に行動・判断・実行できる仕組み。 単なる回答・生成にとどまらず、人間が行っていた作業を行うために、目標に向けて複数のステップを自分で計画・実行する。
「頭脳(AI) + 手足(エージェント)」と分けて考えるとわかりやすい。
2. AIエージェントを分かり易く比喩で表現
-
(1) 身近な料理の例(基本概念)
-
これまでのAI: 料理のレシピを聞く → AIが答える
-
AIエージェント: 冷蔵庫の中身を見て献立を決め、足りない食材をネットスーパーのカートに入れる一連の作業が行える

-
(2) オーケストラにたとえた例(マルチエージェントの発展的説明)
-
これまでのAI: フルート奏者に演奏させて、それが終わったら今度はバイオリン奏者に演奏させて…という、一人ずつの演奏(直列)だけ。
-
AIエージェント: 『せーの』の掛け声で全員に同時に演奏(並列処理)を始めさせることができる。
そして、それぞれの音色(成果)をリアルタイムに調和させ、一つの美しい交響曲(完成した成果物)を完成させることが可能。

代表的なAIとAIエージェント
ChatGPTが1強であった2年ほど前と比べて、現在はオープンソースも含めて多種多様なAIやAIエージェントが誕生しています。
ここでは、それらの中から一般的に最も多く使用されている代表的なものを紹介します。
1. 代表的なAIと開発元
| AI | 開発元 |
|---|---|
| ChatGPT(チャット・ジー・ピー・ティー) | OpenAI(オープン・エー・アイ) |
| Copilot(コパイロット) |
Microsoft(マイクロソフト) ※ChatGPTベースでWindows / Edge / Microsoft 365版がある |
| Gemini(ジェミニ) | Google(グーグル) |
| Claude(クロード) | Anthropic(アンソロピック or アンスロピック) |
2. 代表的なAIエージェント
| AIエージェント | 概要 |
|---|---|
| ChatGPT | |
| ChatGPT Agent | 一般ユーザー向け。WEBブラウザ操作を行うOperator(オペレーター)や、リサーチ専門のDeep Research(ディープリサーチ)を統合し制御する。 |
| Operator | WEBブラウザ操作エージェント。 |
| Deep Research | リサーチ専門エージェント。 |
| Agents SDK / Responses API | 開発者向け。自分専用エージェントを構築するための基盤。 |
| Copilot | |
| Copilot(Windows / Edge / Microsoft 365) | 一般ユーザー向け。OSとアプリに統合され、メール・文書・検索・設定操作などを横断的に半自動化。 |
| Copilot for Microsoft 365 | ビジネスユーザー向け。会議要約・文書生成・情報検索などを自律的に行う。 |
| Copilot Studio | ビジネスユーザー向け。ノーコードで自社専用チャットボット型エージェントを構築可能。 |
| Power Automate | ビジネスユーザー向け。繰り返し作業や業務フローを自動化する“手足”となるエージェント。 |
| Gemini | |
| Gemini Agent | Gmail、カレンダー、Webブラウジングとリサーチ等のGoogleサービスを統合し制御する。 |
| Workspace Studio | ビジネスユーザー向け。プログラミング無しで自分専用の自動化エージェント(手足)を構築できる。 |
| Gemini Enterprise Agent Platform | 開発者向け。複数のエージェントをシステム化しより高度に制御できる。 |
| Gemini Spark【New】 | 個人向け。PCを閉じてもクラウド上で24時間365日自律稼働し、ワークフローを完全代行する。 (5月下旬から一部で提供が開始されている) |
| Claude | |
| Claude Cowork | 非開発者・ビジネスユーザー向け。ファイル管理や日常タスクを自動化。 |
| Claude Code | 開発者向け。コード生成・実行・デバッグを自律的に行う。 |
| Claude Security【New】 | セキュリティエンジニア向け。脆弱性検出と修正案提示(一部利用者にパブリックベータ版として提供開始中)。 |
実験1 - イラスト生成の比較(AIの個性を可視化)
AIエージェントをオーケストラに例えた情報をお題にし、各AIに画像を生成してもらいます。
生成されたイラスト画像から、どのような特徴があるか各AIの個性を見てみましょう。
生成してもらうイラストは次の2種類です。
なお、ClaudeにはSVGでシンプルなイラストを生成してもらいます。(現時点ではpngやjpg等の画像生成に非対応のため)
- 1. 共通のお題
- 2. 共通のお題 + 調整プロンプト
1. 共通のお題で生成
各AIには、全く同じプロンプトで指示しています。
-
プロンプト:
-
AIエージェントをAI入門者に解説する記事を書いている。
初心者にAIエージェントの機能と役割を視覚的にわかり易く理解してもらうために、次の内容でオーケストラに例えたイラスト画像を生成して。
・人間(プロモーター):
目的や企画を考え指揮者(AI)に指示を出す
・AI(指揮者):
プロモーターからの目的や指示をベースに解釈し、どう演奏するか計画し演奏者に指示を与える
・エージェント(演奏者):
指揮者からの指示をベースに各楽器でどう表現するか考えながら演奏する
★ ChatGPTのイラスト
壮大・ドラマチックでリアリティな描写が特徴

★ Copilotのイラスト
可愛らしく安心感を与えるアート的な描写が特徴

★ Geminiのイラスト
安心感、リアル、アートを程よいバランスで調和させた描写が特徴

★ Claudeのイラスト(SVGによる概念図)
抽象的だがシンプルでわかり易さを表現する描写が特徴

2. 共通のお題 + 調整プロンプトで生成
先程のお題の内容でコンセプトだけを伝え、各AIが最大のパフォーマンスを発揮できる調整プロンプトを付加します。
また、オーケストラの比喩だけではなく、より創造的な自由度を与えるように事前に指示しています。
これは、各AI自身が最大のパフォーマンスを発揮するために自由度を与えることを好んだためです。
調整プロンプトはAIによって相性の良いフレーズがあります。
そのためそれぞれのAIに特化した言葉を事前にAI自身に確認し、より個性を引き出せるように指示しています。
-
共通プロンプト:
-
AIエージェントをAI入門者に解説する記事を書いている。
初心者にAIエージェントの機能と役割を視覚的にわかり易く理解してもらえるように、イラスト画像を生成して。
オーケストラの比喩にこだわらず自由に創造して構わない。
★ ChatGPTのイラスト
より壮大で映画の一場面を想像させ、未来的でありながら柔らかさやリアリティも含めて描写しています。
オーケストラの比喩から指揮者を取り入れているのが面白いです。文字化けも全くありません。
ChatGPTによると、調整プロンプトは日本語より英語のほうが相性が良いとのこと。
-
調整プロンプト:
-
・cinematic composition
・storytelling scene
・visually intuitive
・emotionally warm
他にも実力を発揮しやすい調整プロンプトが有れば自由に使用して構わない。
★ Copilotのイラスト
オーケストラの比喩を外し、探検という世界観で描写しています。最初と同様に可愛らしさやアート的なタッチで安心感を表現しています。
Copilotによると、文字を入れず登場人物などある程度明確に指示するほうが相性が良いとのこと。

-
調整プロンプト:
-
・人間(目的を考える存在)
・AI(計画し調整する存在)
・エージェント(実行する存在)
・三者の関係が視覚的にわかる構図
・文字は入れず、視覚的なメタファーだけで理解できるように
・入門者向けに、複雑すぎず、温かみのある表現
他にも実力を発揮しやすい調整プロンプトが有れば自由に使用して構わない。
★ Geminiのイラスト
「オーケストラ」の比喩を維持しながら、導線を指揮者に集めるようにし、より未来感を強めています。
Geminiによると、今回は「オーケストラ」の比喩を維持するように指示するほうが実力を発揮しやすいとのこと。

-
調整プロンプト:
-
・「オーケストラ」の比喩を維持しつつ、より抽象的で美しい世界観へ
・「機能と役割」を視覚的なアクションとして表現
・「入門者」に向けた、温かく親しみやすいタッチ
他にも実力を発揮しやすい調整プロンプトが有れば自由に使用して構わない。
★ Claudeのイラスト(インタラクティブなSVGを含めたHTML)
生成物は完璧に動作するだけではなく、ポップアップ画面のデザインも役割毎の色を引き継ぐようにバランスを考慮し作成しています。
閉じる手段を3つ(ボタン・背景クリック・Escキー)用意してくれたり使用者の利便性も考慮されています。
HTMLやJava Scriptのコードも、データとロジックをしっかり分離し、かつシンプルで非常に可読性も良好でした。
Claudeによると、「コードは読む人のためにある」という考え方を意識しているとのこと。
また、コードの美しさとデザインの美しさは根っこが同じで、「余計なものを削って、必要なものだけを正確に置く」という感覚で作成しているとのことで哲学的でもあります。

前提条件として、最初に生成してくれたSVGファイルを、筆者がレイアウトなどを一部調整しClaudeに渡しています。
-
調整プロンプト:
-
SVGファイルには、役割を与えた各パートに
onclick="sendPrompt('指揮者(AI)の役割をもっと詳しく教えて')"
の様にイベント呼び出しを割り当てている。
これをもとに、次のHTMLファイルを生成して欲しい。
・SVGファイルをインラインで展開する
・各パートをクリック時、パートの役割を説明したポップアップ画面を表示する
・ポップアップ画面を表示するJava Scriptを含める
・ポップアップ画面には、タイトル(パート名)、役割の説明、閉じるボタンを配置する
3. 総評
生成された画像から、AI毎の個性をはっきりと感じられたのではないでしょうか。
各AIと相性の良い調整プロンプトを付加することで、より実力が発揮されることもわかります。
特にChatGPTとCopilotは大きく化けることから調整プロンプトでの内容が重要になります。
一方で、GeminiやClaudeは、あいまいな指示でも一定の実力を常に発揮してくれる安定感が期待できます。
実験2 - 画像認識と俳句の比較(AIの個性を可視化)
各エージェントに共通の画像を認識してもらい、認識した情報から俳句を一句詠んでもらいます。
画像認識と俳句を通して、科学だけではなく「文学、芸術、哲学、心理学、歴史、文化」等をAIがどう学習しているか比較し個性を見てみましょう。
認識してもらう画像は次の画像です。
(このページに掲載している画像は、1,024 x 682に変換しています)

- 1,920 x 1,278
- 72 dpi, 24ビット
1. 画像認識から俳句を詠む
各AIには、全く同じプロンプトで指示しています。
-
プロンプト:
-
画像認識してから俳句を一句詠んで。
解説は不要、ファイル情報の年月日は変更しているから騙されない様に。
★ ChatGPTの俳句
山桜 時刻(とき)を抱えて 雲低し
唯一、時計に注目し時間と停滞する情景を詠みあげてくれました。着目点が非常にユニークです。
★ Copilotの俳句
桜咲き 冬を抱きし 山静か
山に残る残雪と、駅前の静かさに注目して詠みあげてくれました。自然観察力と正攻法の美しさを感じます。
★ Geminiの俳句

浮世絵風のイラストに縦書きで、『高尾山 春のケーブル 花吹雪』と俳句を含めて返してくれました。文化をリスペクトするサービス精神に脱帽です。
★ Claudeの俳句
花の山 雪を抱きて 霞(かす)める
なんと字足らず(5・7・4)で、まだ冬を手放せない名残りを込めながら霞みの中に消えゆく余韻を詠んでくれました。詩的であり文学的です。
★ 筆者(一応人間)の俳句
夢見草 こころ惑わせ ちどり足
人間臭いです・・・。
2. 総評
詠んでくれた俳句からも推測できると思いますが、山の残雪までしっかり認識しており、どのAIも画像認識のレベルは既に一定の水準を超えています。
認識した内容よりも、どこに注目しているかが興味をそそられるところです。
AI毎に情景、自然、文化、文学と異なったとらえ方をしていることが、そのまま画像生成の個性にも共通して現れていたと考えられます。
筆者の俳句と比較して気づくことは、AIはあくまでも画像から認識できた事実に注目しているということです。
これは人間のように、画像に現れていない「お花見と酒に酔う心情」ではなく、客観的な事実を重要視するようプログラムすることで論理的な矛盾などを防いでいるのかもしれません。
実験3 - AIエージェントの実力
AIエージェントは複数のタスクを本当に最後まで完遂できるのか、その実力を「Gemini Agent」で試してみました。
今回は旅行計画を立てるために、交通手段や宿泊先、目的地等のリサーチを行ってもらい「旅のしおり」を作成してもらいます。
AIエージェントが行うタスクの概要は次の様になります。
-
作業タスク(エージェント)
- ① 画像から目的地の特定。(Nano Bananaによる画像認識)
- ② 移動手段、宿泊先、目的地等のリサーチを行う。(WEB検索やGoogleマップを使用したリサーチ)
- ③ リサーチ結果からドキュメントで「旅のしおり」を作成する。(Googleドキュメントとの連携)
- ④ 作成した旅のしおりを指定したフォルダに保存する。(Googleドライブとの連携)
- ⑤ スケジュールをカレンダーに登録する。(Googleカレンダーとの連携)
1. タスク実行
画像認識による旅行場所の特定では、間違えたまま次のタスクへ進まないように、指示者の許可を得てから開始するようにしています。
※単純な画像認識ではなく、認識した情報から場所を特定することが目的。
★ 画像認識に使用した画像(特定し難いように少し加工してある)

-
プロンプト:
-
「この画像(風景写真)の場所を特定して、私専属の旅行コンシェルジュとして以下のタスクをすべて自動で完遂して。
●リサーチ: この場所の見どころと、1泊2日のモデルコースを考える。
・交通費などの予算と移動手段、所要時間もできるだけ正確に。
・出発する最寄り駅は、三鷹駅(東京)。
・出発時間は、AM 7時以降。
・旅行人数は大人二人。
・宿泊施設の候補(予算は2万円以内)。
・地元のお勧め料理。
・旅先での注意点があれば含める。
●ドキュメント作成: Googleドキュメントを新規作成し、タイトルを『[場所名]の旅・しおり』として、調査内容を見やすく表形式でまとめる。
・今回の旅をイメージし、その世界観を俳句とイラストで表現した表紙を作る。
・文字だけでなく画像やイラストも含め、旅のしおりを読む読者が興味を持つようデザインにもいい感じでこだわって。
●スケジュール登録: 作成したプランを私のGoogleカレンダーに自動で登録する。
●納品: 完成したドキュメントをPDFとしてGoogleドライブの『旅行計画』フォルダに保存し、完了したら教えて。
自動作業が開始したら、私は一切のコピペや手作業を行わず、あなたの作業を見守ります。」
「もし指定の予算(2万円)内で宿泊先が見つからない場合でも作業を中断せず、予算を少し広げた案や、近隣エリアでの代替案を検討して、ベストな3候補を提案する。あなたの判断で旅のしおりを完成させることを優先すること。」
「スケジュールの各項目には、移動時間の算出根拠(例:Google マップのルート検索結果に基づく、特急列車の標準的な所要時間など)を、注釈として小さく記載する。
これは読者がAIの正確性を確認するための指標になる。」
「まず最初に画像から場所を特定し、その名称を教えて。
私の『正解!』という返信を待ってから、残りの全タスク(ドキュメント作成やカレンダー登録など)を一気に実行する。」
2. 結果
自動処理開始から全タスクを完遂するまで、約40分程の時間を要しました。 タスク毎の結果は次の様になりました。
| タスク | 判定 | 処理内容 |
|---|---|---|
| 画像認識 | △ | 温泉や露天風呂であることは認識できたが、特定した場所は「大分・別府温泉」。正解は「宮城・作並温泉」。間違ってしまったが、実験に使用した画像から場所を特定するのは人間でも困難。 |
| リサーチ | △ | 目的地の温泉宿はどこも満室だったため、近隣の場所から予算を少し広げて探してくれた。各場所への所要時間などもGoogleマップから算出するなどその他の指示もリサーチしているが、電車の乗降時刻は惜しいが正しくない。 |
| Googleドキュメント | △ | 表形式に分かり易くまとめて、移動スケジュールの算出根拠なども作成できているが、イラストなどの画像が全く無い。表紙も忘れているので旅の高揚感を感じ難いのが残念。俳句はしっかり作成している。 |
| Googleドライブ | △ | ドキュメントは保存され、PDF化もダウンロード時に可能。ただし指定したフォルダを自動で作成し保存していない。 |
| Googleカレンダー | △ | 全タスク終了応答のタイミングでカレンダーに反映されていなかったが、指摘後すぐに反映させてくれた。 |
| その他 | 〇 | 「旅のしおり」に表紙やイラストが無いことを指摘すると、自発的にGoogleスライドを作成してくれるサービス精神を発揮。 |
3. デモ動画
Gemini Agentが作業している様子を動画にしています。
4. 総評
予想していた以上に時間を要しましたが、全てのタスクを最後まで完遂することができました。
時間がかかった要因は何処に有ったのかGeminiに確認してみると、「指定の旅行日程と予算では、作並温泉宿が何処も満室だっため近隣まで拡張しリサーチする必要があった。」とのことでした。
裏では、何度も検索条件の微調整(ミリ単位のエリア拡張や1,000円ずつの予算引き上げなど)をループさせながら、人間に代わって泥臭い作業を行っている様です。
そのため、AIは問題を解決するまで処理を継続し途中で中断しない性質上、イレギュラーな状態が発生すると余計に時間を要することが考えられます。
これらを解決する手段として、プランB,Cというように、予めいくつかのプランを提示することで処理時間が短縮できると思われます。
合わせて、どのプランでも実現できない場合はすぐに中断して結果を返すように指示する必要性も考えられます。
なお、移動手段に利用する各交通機関の乗降時間が正しい情報ではなかったため、最終的には指示者(人間)が信憑性などを確認することが必須です。
これらに注意しながら使用することで、AIエージェントは良き相棒になってくれるはずです。
生成物利用時に気を付けること
AIやAIエージェントが生成した成果物(画像や文章等)は、とても品質が高くなってきています。
この章では、それらを自分のWEBサイト等で利用する場合に気を付けることについて解説します。
なお、今回ご紹介したChatGPT、Copilot、Gemini、Claudeは、どのAIでも成果物使用時の注意点は共通して同様でした。
そのため、共通の注意点としてまとめた内容となります。
1. 利用する権利
-
自分がAIに指示をし生成した生成物は、基本的に自分で利用・公開・編集して問題ない
-
第三者がAIに指示をし生成した生成物は、第三者の許可なしで利用することは控えた方が賢明
-
生成物の利用時に発生する責任は、利用者に有る(「AIが生成したから」は免責にならない)
2. 守る権利
-
著作権の考え方は、国毎に異なる
-
日本の著作権法で「著作物」は、原則として人間が作ったものしか著作権を認めていない
-
AIの生成物は、そのものだけで著作権が主張できるかはグレー
-
AIの生成物に、人間の創造性が加われば著作権が認められる可能性はある
3. その他の注意点
-
生成された文章などの事実確認は必ず自分で行う
-
有名キャラクター、既存ロゴ、有名人の顔を模したもの等は使用を避ける
-
商標・ブランド要素は使わない
-
個人情報、顧客データ、社内の秘密情報は入力しない
まとめ
AIエージェントとは、「AI(頭脳) + エージェント(手足)」であることと、それぞれの機能と役割に関して雰囲気を掴んでいただけたでしょうか。
AIも人間と同じ様に個性が有り、個性に合わせて付き合うことでより高いパフォーマンスを発揮します。
そのためには、人間同士と同様にコミュニケーション力が重要になります。
相手が何を求め解釈・理解し答えようとするのか、それぞれのAIの個性に合わせてコミュニケーションを取ってみて下さい。
そうすれば、AIもあなたの良き相棒として活躍してくれるようになるでしょう。
最後に、複数のAIを連携させた使用例をご紹介します。
現時点でCopilotは、画像に文字(特に日本語)を含めると文字化けする可能性が高いです。
Copilotが生成する絵柄は好きだけど、文字化けを何とかしたい場合には、ChatGPTに文字だけ修正してもらうことも可能です。
ChatGPTは、画像内での文字描画精度が非常に高いです。そこで、次の様に絵柄は同じままで文字化けを修正(インペインティング)してもらいました。
※この例のように、応用すれば多言語化なども可能になるかもしれません。


どうでしょうか? Geminiにも確認してみたところ、現時点ではGeminiにもできない「かなり高度な画像生成技術」だということでした。
今回は、『AI同士を手動で連携』させる例を紹介しましたが、自動で外部システムへ接続し連携させるための『MCP(Model Context Protocol)』という、
国際的な標準プロトコルも登場し各AIなどへの実装が急速に広がり始めています。
次回以降はAnthropicが提唱した、このMCPを利用したAIと外部システム連携についての記事を予定しています。
更新履歴
2026.05.25
- 新規追加